Information representation is the procedure used to convey experiences in information utilizing obvious prompts like diagrams, outlines, maps, and numerous others. This is valuable as it helps in natural and simple comprehension of the enormous amounts of information and consequently settle on better choices in regards to it. At the point when we utilize a print enormous number of a dataset then it shortens. In this article, we will perceive how to print the whole pandas Dataframe or Series without Truncation.
Printing a huge pandas DataFrame that surpasses the predefined number of lines and segments to show brings about a shortened perspective on the DataFrame. Printing a whole DataFrame brings about each line and segment of the DataFrame being printed.
Naturally our total substance of out dataframe are not printed, yield got shortened. It printed just 10 lines (first and last 5 lines) rather than 63 and 12 segments rather than complete 27, every one of the excess information is shortened. Presently imagine a scenario where we need to print the full dataframe for example each of the 63 lines and 27 segments with no truncation?
How to print an entire Pandas DataFrame in Python?
Pandas dataframe is a 2-layered table organized information structure used to store information in lines and sections design. You can pretty print pandas dataframe utilizing pd.set_option(‘display.max_columns’, None) explanation. Usecase: Your dataframe may contain numerous segments and when you print it typically, you’ll just see not many sections. You can set this choice to show all dataframe sections in a jupyter note pad. In this instructional exercise, you’ll gain proficiency with the various strategies to pretty print the Pandas Dataframe.
As a matter of course, the total information outline isn’t printed assuming that the length surpasses the default length, the result is shortened as displayed beneath:
import numpy as npfrom sklearn.datasets import load_irisimport pandas as pd# Loading irirs datasetdata = load_iris()df = pd.DataFrame(data.data, columns = data.feature_names)display(df)Output:
There are 4 strategies to Print the whole pandas Dataframe:
- Use to_string() Method
- Use pd.option_context() Method
- Use pd.set_options() Method
- Use pd.to_markdown() Method
Strategy 1: Using to_string()
While this strategy is easiest of all, it isn’t prudent for exceptionally gigantic datasets (arranged by millions) since it changes over the whole information outline into a string object however functions admirably for information outlines for size in the request for thousands.
Syntax: DataFrame.to_string(buf=None, columns=None, col_space=None, header=True, index=True, na_rep=’NaN’, formatters=None, float_format=None, index_names=True, justify=None, max_rows=None, max_cols=None, show_dimensions=False, decimal=’.’, line_width=None)
Code:
- Python3
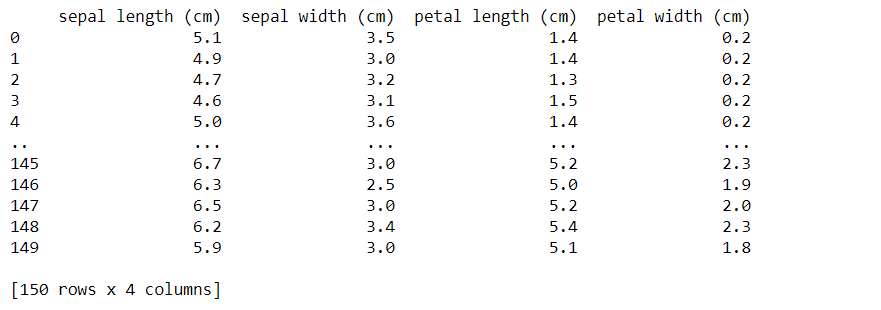
import numpy as npfrom sklearn.datasets import load_irisimport pandas as pddata = load_iris()df = pd.DataFrame(data.data, columns = data.feature_names)# Convert the whole dataframe as a string and displaydisplay(df.to_string()) |
Output:
Technique 2 : Using pd.option_context()
Pandas permit changing settings by means of the option_context() technique and set_option() strategies. Both the strategies are indistinguishable with one distinction that later one changes the settings for all time and the previous do it just inside the setting supervisor scope.
Syntax : pandas.option_context(*args)
Code:
- Python3
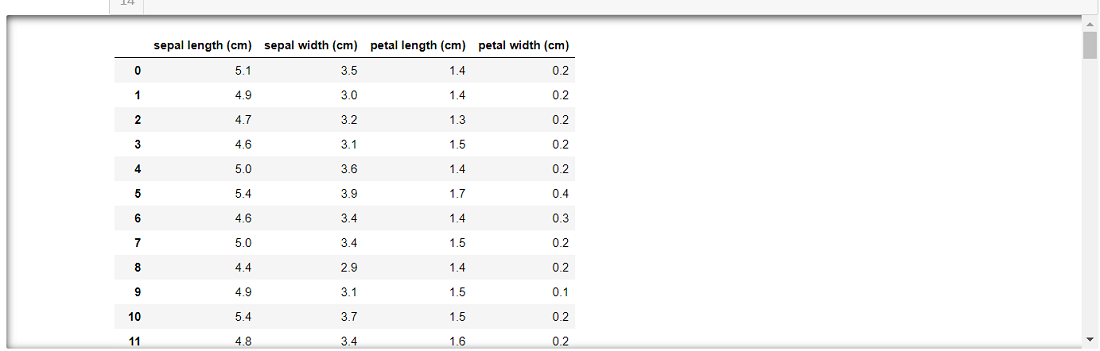
import numpy as npfrom sklearn.datasets import load_irisimport pandas as pddata = load_iris()df = pd.DataFrame(data.data, columns = data.feature_names)# The scope of these changes made to# pandas settings are local to with statement.with pd.option_context('display.max_rows', None, 'display.max_columns', None, 'display.precision', 3, ): print(df) |
Output:
Clarification:
The above code utilizes specific choices boundaries, for example, the ‘display.max_rows’ its default esteem is 10 and assuming the information outline has in excess of 10 lines its shortens it, what we are doing is causing its worth to None to i.e every one of the columns are shown now. Likewise, ‘display.max_columns’ has 10 as default, we are additionally setting it to None.
show. accuracy = 3 demonstrates that later decimal point makes an appearance to 3 qualities here every one of the qualities have 1 worth and accordingly it doesn’t influence this model.
Strategy 3 : Using pd.set_option()
This strategy is like pd.option_context() technique and accepts similar boundaries as examined for strategy 2, yet dissimilar to pd.option_context() its degree and impact is on the whole content i.e every one of the information outlines settings are changed forever
To expressly reset the worth use pd.reset_option(‘all’) technique must be utilized to return the changes.
Syntax : pandas.set_option(pat, value)
Code:
- Python3
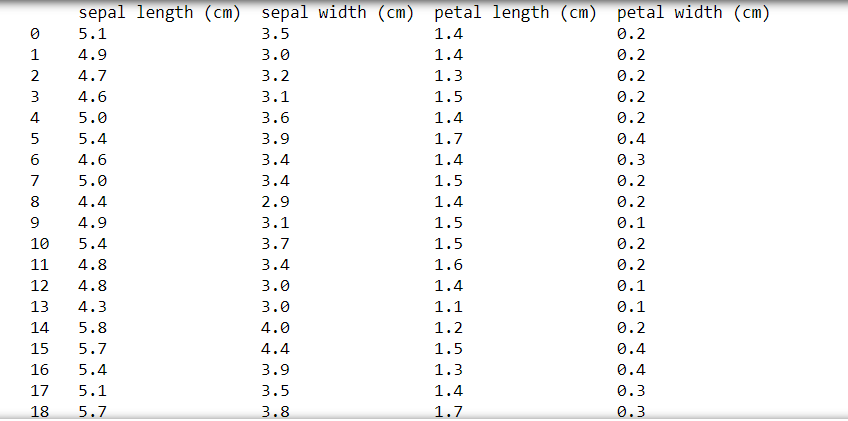
import numpy as npfrom sklearn.datasets import load_irisimport pandas as pddata = load_iris()df = pd.DataFrame(data.data, columns = data.feature_names)# Permanently changes the pandas settingspd.set_option('display.max_rows', None)pd.set_option('display.max_columns', None)pd.set_option('display.width', None)pd.set_option('display.max_colwidth', -1)# All dataframes hereafter reflect these changes.display(df)print('**RESET_OPTIONS**')# Resets the optionspd.reset_option('all')display(df) |
Output:
Technique 4 : Using to_markdown()
This technique is like the to_string() strategy as it additionally changes over the information edge to a string object and furthermore adds styling and organizing to it.
Syntax : DataFrame.to_markdown(buf=None, mode=’wt’, index=True,, **kwargs)
Code:
- Python3
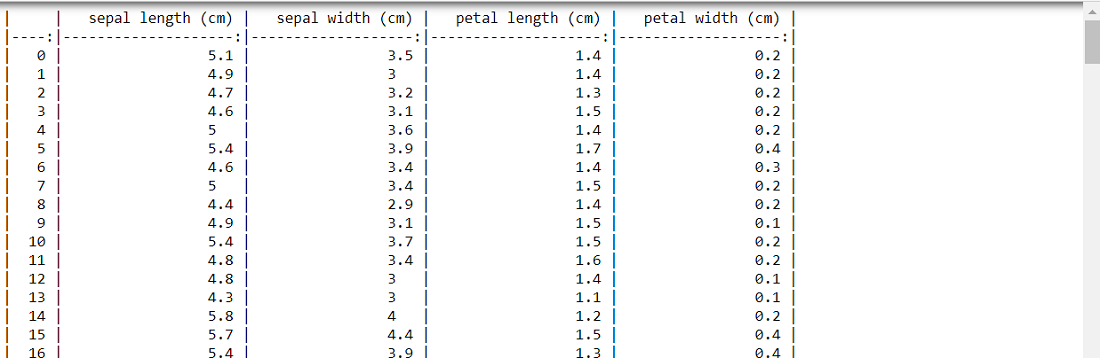
import numpy as npfrom sklearn.datasets import load_irisimport pandas as pddata = load_iris()df = pd.DataFrame(data.data, columns=data.feature_names)# Converts the dataframe into str object with formattingprint(df.to_markdown()) |
Output:
Also Read: How to Create a Social Media App on Android Studio?