Generative Artificial Intelligence (AI)
Generative AI is a type of artificial intelligence that creates new content, such as text, images, audio, or videos, based on patterns and data it has been trained on.
It uses models like large language models or diffusion models to generate outputs that mimic human creativity, such as writing stories, composing music, or designing visuals. Examples include tools like ChatGPT for text or DALL·E for images. It learns from vast datasets to produce novel, often realistic, content tailored to user prompts.
An example of Generative AI is Grok 3, created by xAI. When you ask Grok 3 a question or give it a prompt, it generates human-like text responses based on its training data. For instance, if you ask, “Write a short story about a robot,” Grok 3 can create a unique story on the spot. Another example is DALL·E, which generates images from text prompts, like creating a picture of “a futuristic city at sunset” based on your description.
Evolution of Generative AI
The evolution of Generative AI has been marked by significant milestones, driven by advances in machine learning, computational power, and data availability. Below is a concise overview of its development:
Early Foundations (1950s–2000s)
1950s–1980s: The concept of AI began with rule-based systems and early neural networks. Alan Turing’s work on machine intelligence laid theoretical groundwork. Early models like Markov Chains were used for basic text generation.
1980s–1990s: Neural networks gained traction, but limited computing power and data restricted generative capabilities. Recurrent Neural Networks (RNNs) emerged, enabling basic sequence modeling for tasks like text generation.
2000s: Hidden Markov Models and early machine learning techniques improved natural language processing (NLP) and image generation. Probabilistic models like Bayesian networks were used for simple generative tasks.
Rise of Deep Learning (2010s)
2011–2014: Deep learning revolutionized AI with the success of Deep Neural Networks (DNNs). The introduction of Generative Adversarial Networks (GANs) by Ian Goodfellow in 2014 was a breakthrough, enabling realistic image generation by pitting a generator against a discriminator.
2015–2017: Variational Autoencoders (VAEs) and improved RNNs (e.g., LSTMs) enhanced generative capabilities for text and images. Models like Google’s DeepDream created surreal visuals, showcasing early creative potential.
2017–2018: Transformers, introduced in the paper Attention is All You Need, transformed NLP. Models like Google’s BERT and OpenAI’s GPT-1 leveraged transformers for coherent text generation, marking a shift toward large-scale language models.
Explosion of Large-Scale Models (2018–2022)
2018–2020: GPT-2 by OpenAI demonstrated powerful text generation, capable of writing essays or stories. DALL·E (2021) and StyleGAN by NVIDIA advanced image generation, producing photorealistic visuals. These models scaled up with larger datasets and more parameters.
2021–2022: GPT-3, with 175 billion parameters, set a new standard for text generation, enabling applications like chatbots and code generation. Stable Diffusion and MidJourney democratized image generation, allowing users to create high-quality visuals from text prompts. Multimodal models, combining text and images, began emerging.
Mainstream Adoption and Refinement (2023–2025)
2023: Generative AI became widely accessible. Tools like ChatGPT (based on GPT-4) and Grok 3 by xAI made AI conversational and versatile, with applications in education, business, and creativity. Open-source models like LLaMA fueled innovation.
2024–2025: Advances in efficiency and multimodal capabilities improved. Models now generate video, music, and 3D models alongside text and images. Grok 3, for example, offers text generation with voice mode and deep reasoning capabilities. Ethical concerns, such as bias and misuse, prompted better regulation and fine-tuning techniques like RLHF (Reinforcement Learning from Human Feedback).
Key Trends and Future Directions
Multimodality: Models now integrate text, images, audio, and more, enabling richer outputs (e.g., generating a video from a script).
Efficiency: Techniques like model pruning and quantization reduce computational costs, making generative AI accessible on smaller devices.
Personalization: AI tailors outputs to individual users, improving applications in marketing, education, and entertainment.
Ethical Focus: Ongoing efforts address bias, copyright issues, and environmental impact from training large models.
Real-Time Applications: Integration into platforms like x.com and mobile apps (e.g., Grok 3’s voice mode on iOS/Android) enhances user interaction.
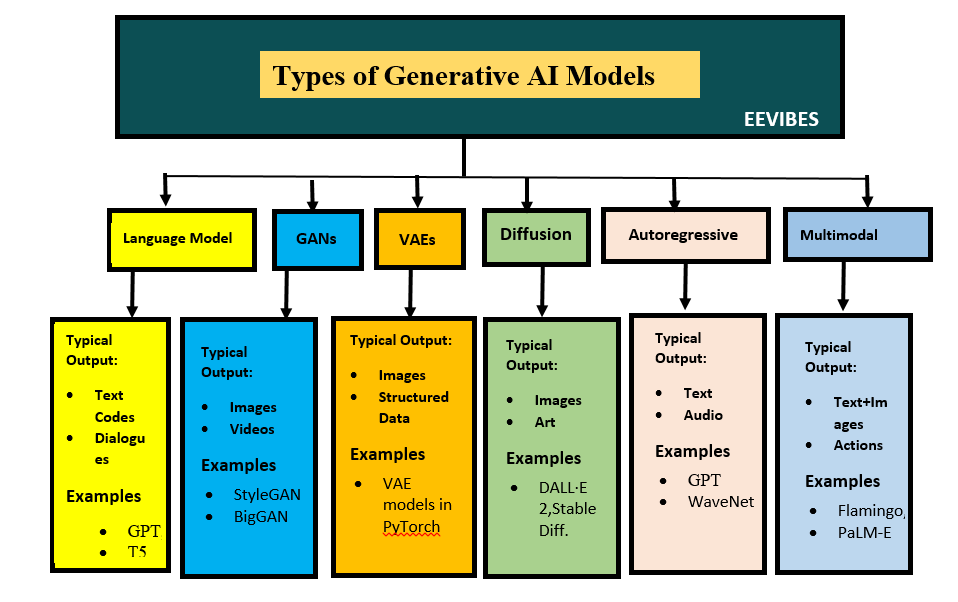
Types of Generative AI Models
Generative AI models are categorized based on their architecture and the type of data they generate. Below is a concise overview of the main types of Generative AI models:
Language Models
Language models are a core category of generative AI designed to understand and generate human-like text by learning patterns from vast text datasets. They operate by predicting word sequences based on context, enabling them to produce coherent and contextually relevant outputs for tasks like conversation, translation, and content creation.
These models typically rely on transformer architectures, which use attention mechanisms to process and generate text efficiently. They are pre-trained on diverse corpora (e.g., web pages, books) to capture general language patterns and fine-tuned for specific applications. While powerful, they can sometimes produce biased or factually incorrect outputs and may struggle with complex reasoning beyond their training data. Language models vary in design and purpose, with different types excelling in specific tasks based on their architecture and training approach.
Examples and Output Types
- Autoregressive Models
- Examples: GPT-3, GPT-4 (OpenAI), Grok (xAI).
- Output Types: Free-form text (e.g., essays, stories, chatbot responses), code snippets, creative writing, or answers to open-ended questions. For instance, Grok can generate concise, truthful answers or elaborate explanations, accessible on grok.com, x.com, or mobile apps with voice mode (app-only) and DeepSearch for web-enhanced responses.
- Use Case Example: Generating a blog post or answering “What is quantum computing?” with a detailed explanation.
- Bidirectional Models
- Examples: BERT (Google), RoBERTa.
- Output Types: Contextual text embeddings for classification, short text for question-answering, or entity labels (e.g., identifying names in text). Less focused on free-form generation but can produce targeted text outputs like sentence completions.
- Use Case Example: Answering “Who is the president in 2025?” by extracting relevant context or classifying sentiment in reviews.
- Seq2Seq (Encoder-Decoder) Models
- Examples: T5 (Google), BART.
- Output Types: Structured text like translations (e.g., English to Spanish), summaries of long documents, or dialogue responses. Outputs are typically concise and task-specific.
- Use Case Example: Summarizing a 1,000-word article into 100 words or translating a sentence like “I love coding” into French (“J’adore coder”).
- Diffusion-Based Language Models
- Examples: Experimental models, less common (e.g., early research from DeepMind).
- Output Types: Refined text outputs, such as polished sentences or stylized text (e.g., poetry in a specific tone). Still emerging, with limited mainstream use.
- Use Case Example: Generating a poem in Shakespearean style from a rough draft.
- Multimodal Language Models
- Examples: GPT-4o (OpenAI), LLaVA.
- Output Types: Text descriptions of images, answers combining visual and textual context, or text guided by visual prompts. Outputs may include captions or narrative text tied to images.
- Use Case Example: Describing a photo as “A serene lake surrounded by mountains at sunset” or answering questions about a chart.
- Efficient/Lightweight Models
- Examples: LLaMA (Meta AI, research-only), DistilBERT, Mistral.
- Output Types: Similar to autoregressive or bidirectional models but optimized for speed, producing shorter text outputs like responses, classifications, or code snippets on resource-constrained devices.
- Use Case Example: Running a chatbot on a mobile device with limited processing power.
2. Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are a class of generative AI models that create new data, such as images, audio, or text, by pitting two neural networks against each other: a generator and a discriminator. The generator produces synthetic data from random noise, while the discriminator evaluates whether the data is real (from the training dataset) or fake (from the generator). Through iterative training, the generator improves its outputs to “fool” the discriminator, resulting in highly realistic data. Introduced by Ian Goodfellow in 2014, GANs are widely used for their ability to generate high-quality, realistic content, though they can be challenging to train due to issues like mode collapse (limited output diversity) or instability.
How GANs Work
- Generator: Takes random input (e.g., noise vector) and generates data (e.g., an image).
- Discriminator: Classifies data as real or fake, providing feedback to the generator.
- Training Process: The two networks are trained simultaneously in a competitive setting, optimizing a minimax loss function. The generator improves as the discriminator gets better at spotting fakes.
- Output: Data resembling the training set (e.g., photorealistic images, synthetic voices).
Examples of GANs
- DCGAN (Deep Convolutional GAN)
- Description: Uses convolutional neural networks for generating images.
- Output Types: High-quality images (e.g., faces, landscapes).
- Use Case Example: Creating realistic human faces for avatars or art.
- CycleGAN
- Description: Enables unpaired image-to-image translation (e.g., turning horses into zebras).
- Output Types: Transformed images (e.g., style-transferred artwork).
- Use Case Example: Converting summer landscapes to winter scenes without paired data.
- StyleGAN (NVIDIA)
- Description: Advanced GAN for high-resolution, controllable image generation.
- Output Types: Photorealistic images with fine-grained control (e.g., facial features, styles).
- Use Case Example: Generating customizable human faces for video games or virtual influencers.
- WGAN (Wasserstein GAN)
- Description: Improves training stability using Wasserstein loss.
- Output Types: Diverse images or data with better quality.
- Use Case Example: Generating synthetic medical images for research.
- Text-to-Image GANs (e.g., DALL·E, Stable Diffusion)
- Description: Combines GAN principles with other architectures (e.g., diffusion models) to generate images from text prompts.
- Output Types: Images based on text descriptions (e.g., “a cat in a spacesuit”).
- Use Case Example: Creating artwork from prompts like “futuristic city at night.”
Output Types
- Images: Photorealistic faces, landscapes, or stylized art (e.g., anime, oil paintings).
- Audio: Synthetic voices, music, or sound effects.
- Text: Less common, but some GANs generate text or augment language models.
- Other: 3D models, videos, or synthetic datasets for simulations.
Strengths and Limitations
- Strengths: Produce highly realistic and creative outputs, especially for visual and auditory data.
- Limitations: Training instability, high computational cost, and potential for generating biased or unethical content (e.g., deepfakes).
3. Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) are a class of generative AI models that generate new data, such as images, text, or audio, by learning a compressed representation of the input data. Introduced by Kingma and Welling in 2013, VAEs combine neural networks with Bayesian inference to model data distributions. They consist of an encoder, which compresses input data into a latent space (a lower-dimensional representation), and a decoder, which reconstructs or generates data from this latent space. Unlike GANs, which use a competitive approach, VAEs optimize a probabilistic framework, balancing data reconstruction with regularization to ensure a structured latent space. This makes VAEs particularly useful for generating diverse outputs and interpolating between data points, though they often produce blurrier results compared to GANs.
How VAEs Work
- Encoder: Maps input data (e.g., an image) to a latent space, outputting parameters (mean and variance) of a probability distribution (typically Gaussian).
- Latent Space: A compact, continuous representation where similar data points are close together, enabling smooth interpolation.
- Decoder: Samples from the latent space to generate new data resembling the training set.
- Training Process: Optimizes two objectives: reconstruction loss (how well the output matches the input) and KL-divergence (ensuring the latent distribution is close to a standard distribution).
- Output: Data similar to the training set, such as images, text embeddings, or audio waveforms.
Examples of VAEs
- Standard VAE
- Description: Basic VAE for generating simple images or data.
- Output Types: Low-resolution images (e.g., handwritten digits from MNIST).
- Use Case Example: Generating synthetic digits for dataset augmentation.
- Conditional VAE (CVAE)
- Description: Generates data conditioned on specific inputs (e.g., labels or attributes).
- Output Types: Images or data tailored to conditions (e.g., generating a “7” digit or a specific face).
- Use Case Example: Creating faces with specific features (e.g., smiling, glasses).
- β-VAE
- Description: Modifies the VAE by adding a parameter (β) to control disentanglement in the latent space, improving interpretability.
- Output Types: Images or data with disentangled features (e.g., separating color and shape).
- Use Case Example: Generating variations of objects (e.g., cars with different colors but same shape).
- VAE for Text
- Description: Adapts VAEs for sequential data like text, often combined with recurrent neural networks (RNNs).
- Output Types: Sentences or text embeddings.
- Use Case Example: Generating coherent sentences for dialogue systems.
- Multimodal VAEs
- Description: Handle multiple data types (e.g., text and images) in a shared latent space.
- Output Types: Cross-modal outputs, like images from text or vice versa.
- Use Case Example: Generating images from captions, similar to text-to-image GANs.
Output Types
- Images: Synthetic images (e.g., faces, objects), often less sharp than GAN outputs but diverse.
- Text: Sentence embeddings or short text sequences (less common than language models).
- Audio: Waveforms or spectrograms for sound generation.
- Other: Structured data, such as molecular structures for drug discovery.
Strengths and Limitations
- Strengths: Stable training, structured latent space for interpolation, and probabilistic outputs for uncertainty estimation.
- Limitations: Blurrier outputs compared to GANs, less effective for high-resolution data, and complex tuning of hyperparameters.
- Diffusion Models
- Autoregressive Models
- Transformers for Multi-modal Generation
Description: Use encoder-decoder architectures to learn latent representations of data, generating new samples by sampling from this latent space.
Applications: Image denoising, data imputation, generating synthetic datasets.
Examples: Beta-VAE, Conditional VAEs.
Strengths: Stable training, good for structured data generation.
Weaknesses: Outputs can be less sharp compared to GANs.
4. Diffusion Models
Diffusion models are a class of generative AI models that create high-quality data, such as images, audio, or text, by modeling a process that gradually transforms random noise into structured data. Introduced in recent years, they have gained prominence for producing photorealistic images and other complex outputs, rivaling GANs in quality while being more stable to train. Diffusion models work by simulating a forward process that adds noise to data and a reverse process that learns to denoise it, reconstructing the original data or generating new samples. They are computationally intensive but excel in generating detailed, diverse outputs, making them popular for applications like text-to-image synthesis.
How Diffusion Models Work
- Forward Process: Gradually adds Gaussian noise to the input data over multiple steps, turning it into random noise.
- Reverse Process: Learns to remove noise step-by-step, reconstructing the original data or generating new samples from noise.
- Training: The model is trained to predict the noise added at each step, optimizing a loss function (e.g., mean squared error) to approximate the reverse process.
- Output: High-quality data resembling the training set, such as images, audio waveforms, or text embeddings.
Examples of Diffusion Models
- DDPM (Denoising Diffusion Probabilistic Models)
- Description: The foundational diffusion model, introduced by Ho et al. (2020), for generating high-quality images.
- Output Types: Photorealistic images (e.g., faces, landscapes).
- Use Case Example: Generating synthetic artwork or faces for creative projects.
- Stable Diffusion
- Description: A latent diffusion model that operates in a compressed latent space, reducing computational cost while maintaining quality.
- Output Types: Images from text prompts (e.g., “a dragon flying over a castle”).
- Use Case Example: Creating custom illustrations for games or marketing based on text descriptions.
- DALL·E 2 (OpenAI)
- Description: Combines diffusion with text conditioning to generate images from textual prompts, leveraging CLIP for guidance.
- Output Types: Highly detailed images tailored to text inputs.
- Use Case Example: Producing concept art like “a futuristic city at sunset.”
- Score-Based Generative Models
- Description: A variant using score functions (gradients of log-probability) to guide the denoising process.
- Output Types: Images, audio, or scientific data (e.g., molecular structures).
- Use Case Example: Generating synthetic medical images for training diagnostic models.
- Diffusion for Text
- Description: Emerging models adapt diffusion for text generation, often combined with language models.
- Output Types: Coherent text sequences or embeddings.
- Use Case Example: Generating stylized text, such as poetry or dialogue, though less common than image applications.
Output Types
- Images: Photorealistic or stylized images (e.g., faces, objects, scenes).
- Audio: High-fidelity waveforms or music (e.g., synthetic speech).
- Text: Sentence embeddings or short text (still experimental, less prevalent than language models).
- Other: Scientific data, such as molecular structures or time-series data.
Strengths and Limitations
- Strengths: High-quality outputs, stable training compared to GANs, and flexibility for conditional generation (e.g., text-to-image).
- Limitations: High computational cost, slow inference (many denoising steps), and complex optimization for non-image data.
5. Autoregressive Models
Autoregressive Models in Generative AI
Autoregressive models are a class of generative AI models that generate data sequentially, predicting each element (e.g., a word, pixel, or audio sample) based on the preceding elements. Primarily used in language modeling, they excel at producing coherent and contextually relevant text by modeling the probability distribution of sequences. These models leverage transformer architectures or recurrent neural networks (RNNs) to capture dependencies in data, making them ideal for tasks like text generation, conversation, and even image or audio synthesis when adapted. While powerful for open-ended generation, they can be computationally intensive and may struggle with long-term dependencies or generating globally consistent outputs (e.g., in images).
How Autoregressive Models Work
- Mechanism: Generate data one step at a time, where each output (e.g., a word) is conditioned on all previous outputs. The model predicts the next element using a probability distribution learned during training.
- Training: Pre-trained on large datasets (e.g., web text, books) to learn general patterns, then fine-tuned for specific tasks. Uses techniques like maximum likelihood estimation or reinforcement learning (e.g., RLHF for alignment).
- Output: Sequential data, such as text, that builds on prior context to maintain coherence.
Examples of Autoregressive Models
- GPT Series (OpenAI)
- Description: Transformer-based models like GPT-3 and GPT-4, designed for text generation and versatile tasks.
- Output Types: Free-form text (e.g., essays, stories, answers), code, or dialogue.
- Use Case Example: Writing a short story or answering “Explain relativity in simple terms.”
- Grok (xAI)
- Description: A transformer-based model focused on concise, truthful answers with reasoning, accessible on grok.com, x.com, and mobile apps (iOS/Android) with free/SuperGrok plans. Features voice mode (app-only) and DeepSearch (UI-activated) for web-enhanced responses.
- Output Types: Conversational responses, explanations, or task-specific text (e.g., summarizing articles).
- Use Case Example: Responding to “What are the benefits of renewable energy?” with a detailed yet concise answer.
- XLNet
- Description: An autoregressive model that incorporates bidirectional context while maintaining sequential generation.
- Output Types: Text for tasks like question-answering or sentiment analysis.
- Use Case Example: Classifying movie reviews as positive or negative.
- PixelRNN/PixelCNN
- Description: Autoregressive models adapted for image generation, predicting pixels sequentially.
- Output Types: Images generated pixel-by-pixel (e.g., low-resolution textures).
- Use Case Example: Creating synthetic textures for video games.
- WaveNet (DeepMind)
- Description: An autoregressive model for audio, generating raw waveforms sample by sample.
- Output Types: High-quality audio, such as synthetic speech or music.
- Use Case Example: Generating realistic human-like speech for virtual assistants.
Output Types
- Text: Coherent sentences, paragraphs, code, or dialogue (e.g., chatbot responses, creative writing).
- Images: Pixel-by-pixel images (less common, lower resolution than GANs or diffusion models).
- Audio: Waveforms for speech or music (e.g., synthetic voices).
- Other: Sequential data like time-series predictions.
Strengths and Limitations
- Strengths: Excellent for sequential tasks like text generation, strong contextual understanding, and flexibility across domains (text, audio, images).
- Limitations: Slow for long sequences due to sequential processing, potential for error accumulation, and less effective for globally coherent outputs (e.g., high-resolution images).
6. Transformers for Multi-modal Generation
Transformers, originally developed for natural language processing, are a cornerstone of generative AI due to their ability to model complex relationships in sequential data using attention mechanisms. For multi-modal generation, transformers are adapted to handle and integrate multiple data types—such as text, images, audio, or video—within a single framework, producing outputs that combine or translate between modalities. These models leverage their ability to capture long-range dependencies and contextual relationships across diverse data, making them ideal for tasks like text-to-image synthesis, image captioning, or video generation. By training on large, diverse datasets, multi-modal transformers generate coherent and contextually aligned outputs, though they require significant computational resources and careful design to align different modalities effectively.
How Transformers for Multi-modal Generation Work
- Architecture: Transformers use encoder-decoder or decoder-only architectures with attention layers to process and generate data. For multi-modal tasks, inputs (e.g., text, images) are encoded into a shared latent space, and the decoder generates outputs in one or more modalities.
- Training: Pre-trained on large multi-modal datasets (e.g., text-image pairs like LAION) to learn cross-modal relationships, then fine-tuned for specific tasks. Contrastive learning (e.g., CLIP) or autoregressive objectives are often used.
- Process: Inputs from one modality (e.g., text) guide generation in another (e.g., images), or multiple modalities are combined to produce a unified output.
- Output: Cross-modal or single-modal data, such as images from text prompts, captions from images, or synchronized audio-visual content.
Examples of Transformers for Multi-modal Generation
- DALL·E 2 (OpenAI)
- Description: Uses a transformer-based architecture with CLIP to generate images from text prompts, leveraging diffusion-like processes.
- Output Types: High-quality images (e.g., “a cat painting in Van Gogh style”).
- Use Case Example: Creating custom artwork for advertising or storytelling.
- CLIP-ViT (OpenAI)
- Description: Combines a vision transformer (ViT) with a text transformer to align images and text in a shared latent space, often used to guide generation in other models.
- Output Types: Image-text embeddings for tasks like image captioning or text-guided image synthesis.
- Use Case Example: Generating captions like “A sunset over a mountain” for a photo.
- LLaVA (Large Language and Vision Assistant)
- Description: A transformer-based model integrating vision and language for multi-modal tasks.
- Output Types: Text responses based on images, or image-guided text generation.
- Use Case Example: Answering “What’s in this image?” with a detailed description or generating a story inspired by a visual scene.
- Flamingo (DeepMind)
- Description: A vision-language transformer for few-shot learning, capable of generating text or answering questions about images.
- Output Types: Text responses, captions, or visual question-answering outputs.
- Use Case Example: Describing a video clip or answering “What is the object in the center of the image?”
- Video Diffusion Transformers (e.g., Sora by OpenAI)
- Description: Extends transformers to video by modeling temporal and spatial relationships, often combined with diffusion techniques.
- Output Types: Short video clips from text prompts (e.g., “a robot dancing in a park”).
- Use Case Example: Generating animated shorts or promotional video content.
Output Types
- Images: Photorealistic or stylized images from text prompts or other images.
- Text: Captions, descriptions, or dialogue based on images or videos.
- Audio: Emerging applications generate audio aligned with text or visuals (e.g., synchronized speech).
- Video: Short clips or animations driven by text or image inputs.
- Cross-modal: Combined outputs, like text and images together (e.g., a story with illustrations).
Strengths and Limitations
- Strengths: Versatile across modalities, excellent at capturing cross-modal relationships, and capable of high-quality, contextually aligned outputs.
- Limitations: High computational cost, complexity in aligning modalities, and potential for biases or misaligned outputs (e.g., incorrect image-text pairing).