Glob function is an overall term used to characterize methods to coordinate with determined examples as per rules identified with Unix shell. Linux and Unix frameworks and shells additionally support glob and furthermore give work glob() in framework libraries.
How to Use Glob() function to find files recursively in Python?
In Python, the glob module is utilized to recover documents/pathnames coordinating with a predefined design. The example rules of glob keep guideline Unix way extension rules. It is additionally anticipated that as indicated by benchmarks it is quicker than different techniques to coordinate pathnames in catalogs. With glob, we can likewise utilize special cases (“*, ?, [ranges]) aside from precise string search to make way recovery more basic and helpful.
The glob module is a helpful piece of the Python standard library. glob (short for worldwide) is utilized to return all document ways that match a particular example.
We can utilize glob to look for a particular record design, or maybe more helpfully, look for documents where the filename coordinates with a specific example by utilizing trump card characters.
As per Wikipedia, “glob designs determine sets of filenames with special case characters”.
- These examples are like customary articulations however a lot less difficult.
- Mark (*): Matches at least zero characters
- Question Mark (?) Matches precisely one person
How to use Glob() function to find files
While glob can be utilized to look for a record with a particular filename, I think that it is particularly helpful for perusing a few documents with comparative names. Subsequent to distinguishing these documents, they would then be able to be linked into one data frame for additional examination.
Here we have an info envelope with a few csv documents containing stock information. How about we use glob to recognize the records:
| import pandas as pd | |
| import glob | |
| # set search path and glob for files | |
| # here we want to look for csv files in the input directory | |
| path = ‘input’ | |
| files = glob.glob(path + ‘/*.csv’) | |
| # create empty list to store dataframes | |
| li = [] | |
| # loop through list of files and read each one into a dataframe and append to list | |
| for f in files: | |
| # read in csv | |
| temp_df = pd.read_csv(f) | |
| # append df to list | |
| li.append(temp_df) | |
| print(f’Successfully created dataframe for {f} with shape {temp_df.shape}‘) | |
| # concatenate our list of dataframes into one! | |
| df = pd.concat(li, axis=0) | |
| print(df.shape) | |
| df.head() | |
| >> Successfully created dataframe for input/KRO.csv with shape (1258, 6) | |
| >> Successfully created dataframe for input/MSFT.csv with shape (1258, 6) | |
| >> Successfully created dataframe for input/TSLA.csv with shape (1258, 6) | |
| >> Successfully created dataframe for input/GHC.csv with shape (1258, 6) | |
| >> Successfully created dataframe for input/AAPL.csv with shape (1258, 6) | |
| >> (6290, 6) |
Here we read in all the csv records in our feedback envelope and linked them into one dataframe.
We can see a little issue with this in the example yield beneath — we don’t realize which record the column has a place with. The stock ticker was just the name of each document and is excluded from our connected dataframe.
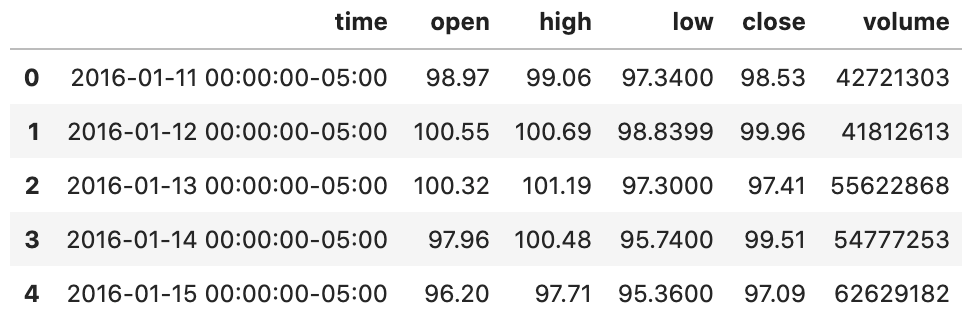
We can tackle the issue of the missing stock ticker by adding an extra segment with the ticker image.
We make another segment with the filename, then, at that point, use supplant to clean the information, eliminating the undesirable record augmentation:
| import pandas as pd | |
| import glob | |
| # set search path and glob for files | |
| # here we want to look for csv files in the input directory | |
| path = ‘input’ | |
| files = glob.glob(path + ‘/*.csv’) | |
| # create empty list to store dataframes | |
| li = [] | |
| # loop through list of files and read each one into a dataframe and append to list | |
| for f in files: | |
| # get filename | |
| stock = os.path.basename(f) | |
| # read in csv | |
| temp_df = pd.read_csv(f) | |
| # create new column with filename | |
| temp_df[‘ticker’] = stock | |
| # data cleaning to remove the .csv | |
| temp_df[‘ticker’] = temp_df[‘ticker’].replace(‘.csv’, ”, regex=True) | |
| # append df to list | |
| li.append(temp_df) | |
| print(f’Successfully created dataframe for {stock} with shape {temp_df.shape}‘) | |
| # concatenate our list of dataframes into one! | |
| df = pd.concat(li, axis=0) | |
| print(df.shape) | |
| df.head() | |
| >> Successfully created dataframe for KRO.csv with shape (1258, 7) | |
| >> Successfully created dataframe for MSFT.csv with shape (1258, 7) | |
| >> Successfully created dataframe for TSLA.csv with shape (1258, 7) | |
| >> Successfully created dataframe for GHC.csv with shape (1258, 7) | |
| >> Successfully created dataframe for AAPL.csv with shape (1258, 7) | |
| >> (6290, 7) |
This looks much better! We would now be able to tell which ticker each column has a place with!
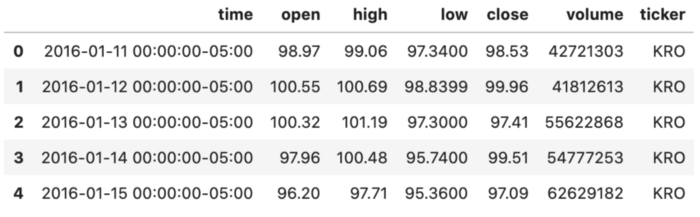
Presently we have a valuable dataframe with all our stock information. This would then be able to be utilized for additional investigation.
The glob module is additionally extremely helpful for tracking down text in documents. I use glob broadly to distinguish records with a coordinating with string.
(Many, commonly, I realize I’ve as of now composed code that I really want, yet can’t recollect where to track down it, or I really want to find each program that contains a specific email address or h̵a̵r̵d̵-̵c̵o̵d̵e̵d̵ esteem that should be taken out or refreshed.
To start with, we can utilize glob to find all documents in a catalog and its sub-registries that match a hunt design. Then, at that point, we read the document as a string and quest for the coordinating with search design.
For instance, I realize I made a KDE plot previously, however I can’t recollect where to track down it.
| import pandas as pd | |
| import glob | |
| # set filepath to search | |
| path = ‘/Users/tara/ml_guides/’ + ‘**/*.ipynb’ | |
| # string to search for | |
| search_term = ‘kdeplot’ | |
| # empty list to hold files that contain matching string | |
| files_to_check = [] | |
| # looping through all the filenames returned | |
| # set recursive = True to look in sub-directories too | |
| for filename in glob.iglob(path, recursive=True): | |
| # adding error handling just in case! | |
| try: | |
| with open(filename) as f: | |
| # read the file as a string | |
| contents = f.read() | |
| # if the search term is found append to the list of files | |
| if(search_term in contents): | |
| files_to_check.append(filename) | |
| except: | |
| pass | |
| files_to_check | |
| >> [‘/Users/tara/ml_guides/superhero-exploratory-analysis.ipynb’, | |
| ‘/Users/tara/ml_guides/glob/glob_tutorial.ipynb’] |
We found two records that contain the string ‘kdeplot’! The document, superhero_exploratory_analysis.ipynb ought to be the thing we’re searching for.
The other document — glob_tutorial.ipynb is the name of the record where this model resides, so it’s certainly not the case of making KDE plots that we’re searching for.
Two things in this model vary from the abovementioned: We indicated recursive=True and utilized iglob rather than glob.
Adding the contention recursive=True advises glob to look through all subdirectories just as the ml_guides registry. This can be exceptionally useful on the off chance that we aren’t sure precisely which envelope our hunt term will be in.
At the point when the recursive contention isn’t determined, or is set to False, we just hunt in the envelope indicated in our pursuit way.
Looking through countless catalogs could consume a large chunk of the day and utilize a ton of memory. An answer for this is to utilize iglob.
iglob contrasts from glob in that it returns an iterator “which yields similar qualities as glob without putting away them all at the same time” as per the documentation. This ought to give further developed execution versus glob.
End
Here we audited Python’s glob module and two use cases for this incredible resource for Python’s standard library.
We showed the utilization of glob to find all documents in an index that match a given example. The documents were then connected into a solitary dataframe to be utilized for additional examination.
We likewise talked about the utilization of iglob to recursively scan numerous registries for documents containing a given string.
This aide is just a short glance at some potential employments of the glob module. I couldn’t want anything more than to see the manners in which you concoct for utilizing it!
Also Read: How To Convert Python Dictionary To JSON?