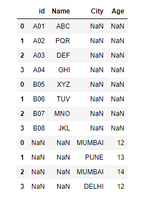
import pandas as pd# First DataFramedf1 = pd.DataFrame({'id': ['A01', 'A02', 'A03', 'A04'], 'Name': ['ABC', 'PQR', 'DEF', 'GHI']}) # Second DataFramedf2 = pd.DataFrame({'id': ['B05', 'B06', 'B07', 'B08'], 'Name': ['XYZ', 'TUV', 'MNO', 'JKL']}) frames = [df1, df2] result = pd.concat(frames)display(result) |
Output:
Joining DataFrames
At the point when we linked our DataFrames we essentially added them to one another for example stacked them either in an upward direction or next to each other. One more method for consolidating DataFrames is to involve segments in each dataset that contain normal qualities (a typical special id). Consolidating DataFrames utilizing a typical field is classified “joining”. The sections containing the normal qualities are designated “join key(s)”. Joining DataFrames in this manner is regularly helpful when one DataFrame is a “query table” containing extra information that we need to remember for the other.
Note: This course of joining tables is like how we manage tables in a SQL information base.
While sticking together numerous DataFrames, you have a decision of how to deal with different tomahawks (other than the one being connected). This should be possible in the accompanying two ways :
Take the association of all, join=’outer’. This is the default choice as it brings about zero data misfortune.
Take the crossing point, join=’inner’.
Example:
- Python3
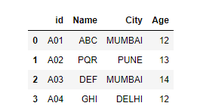
import pandas as pd df1 = pd.DataFrame({'id': ['A01', 'A02', 'A03', 'A04'], 'Name': ['ABC', 'PQR', 'DEF', 'GHI']}) df3 = pd.DataFrame({'City': ['MUMBAI', 'PUNE', 'MUMBAI', 'DELHI'], 'Age': ['12', '13', '14', '12']}) # the default behaviour is join='outer'# inner join result = pd.concat([df1, df3], axis=1, join='inner')display(result) |
Output:
Concatenating using append
A useful shortcut to concat() is append() instance method on Series and DataFrame. These methods actually predated concat.
Example:
- Python3
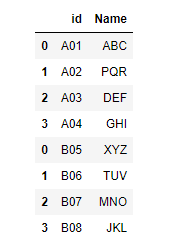
import pandas as pd# First DataFramedf1 = pd.DataFrame({'id': ['A01', 'A02', 'A03', 'A04'], 'Name': ['ABC', 'PQR', 'DEF', 'GHI']}) # Second DataFramedf2 = pd.DataFrame({'id': ['B05', 'B06', 'B07', 'B08'], 'Name': ['XYZ', 'TUV', 'MNO', 'JKL']}) # append methodresult = df1.append(df2)display(result) |
Output:

Note: append() may take multiple objects to concatenate.
Example:
- Python3
import pandas as pd# First DataFramedf1 = pd.DataFrame({'id': ['A01', 'A02', 'A03', 'A04'], 'Name': ['ABC', 'PQR', 'DEF', 'GHI']}) # Second DataFramedf2 = pd.DataFrame({'id': ['B05', 'B06', 'B07', 'B08'], 'Name': ['XYZ', 'TUV', 'MNO', 'JKL']}) df3 = pd.DataFrame({'City': ['MUMBAI', 'PUNE', 'MUMBAI', 'DELHI'], 'Age': ['12', '13', '14', '12']}) # appending multiple DataFrameresult = df1.append([df2, df3])display(result) |
Output: