Feature extraction is a key process in machine learning and computer vision. It involves transforming raw data into a set of measurable and meaningful attributes or characteristics—called features—that can be used for further analysis, such as classification or prediction.
The main goal of feature extraction is to reduce the complexity of the data while retaining the most important information that helps in distinguishing patterns or classes.
Examples of Feature Extraction
- For example, in image processing, features may include edges, textures, shapes, or color histograms that capture the essential structure of the image.
- In text analysis, features could be word frequencies, sentence length, or sentiment scores.
Effective feature extraction not only improves the performance and accuracy of machine learning models but also speeds up computation by reducing the dimensionality of the input data.
This step is often followed by feature selection or dimensionality reduction techniques like PCA (Principal Component Analysis) to refine the input further.
Overall, feature extraction plays a critical role in building intelligent systems by bridging the gap between raw data and actionable insights.
Feature Extraction Example: Handwritten Digit Recognition
Context
In a handwritten digit recognition task (e.g., using the MNIST dataset), each digit is represented as a 28×28 pixel grayscale image, resulting in 784 raw pixel values. Feature extraction transforms this high-dimensional raw data into a smaller, more meaningful set of features to improve model performance.
Example
- Raw Data: The original 28×28 image is flattened into a vector of 784 pixel intensities (values from 0 to 255).
- Feature Extraction Process: Instead of using all 784 pixels, we extract key features, such as:
- Number of closed loops (e.g., 1 for digit 8, 0 for digit 1).
- Presence of vertical or horizontal lines (binary: 1 if present, 0 if not).
- Pixel density in four quadrants of the image (average intensity in each quadrant).
- Total number of non-zero pixels (indicating the “ink” used).
These features reduce the data to, say, 10-20 values that capture the digit’s essential characteristics.
- Alternative (Automated): A convolutional neural network (CNN) could extract features like edges or shapes by applying filters, producing compact feature maps (e.g., 32x32x3 values).
Benefits
This process reduces dimensionality (from 784 to 10-20 features), eliminates noise (e.g., background pixels), and focuses on discriminative patterns, improving model efficiency and accuracy.
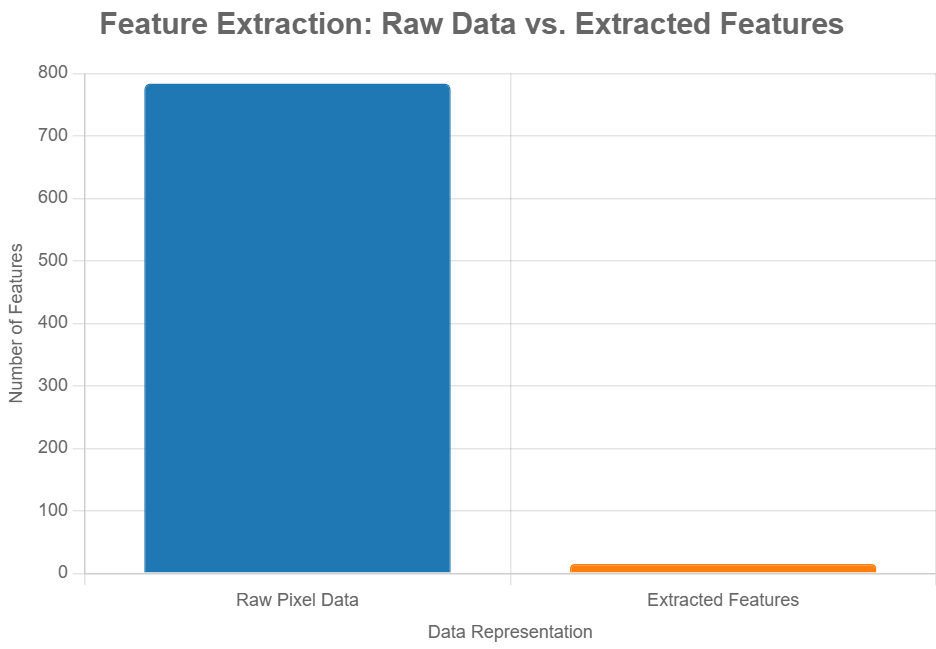
Visualization: Raw Data vs. Extracted Features
| Aspect | Raw Pixel Data | Extracted Features |
|---|---|---|
| Data Size | 784 values (28×28 pixels) | 10-20 values (e.g., loops, lines, density) |
| Content | Pixel intensities (0-255) | High-level attributes (e.g., 1 loop, 2 lines) |
| Noise | Includes background noise | Noise reduced (focus on key patterns) |
| Computation | High (processes all pixels) | Low (processes fewer features) |
| Interpretability | Low (raw pixels are abstract) | Higher (features like loops are meaningful) |
This table illustrates how feature extraction simplifies the data while retaining critical information for digit classification.
Explanation of the Chart
This bar chart compares the number of features used in the handwritten digit recognition example:
- Raw Pixel Data: Represents the 784 pixel values from a 28×28 grayscale image (as in the MNIST dataset).
- Extracted Features: Represents approximately 15 features (e.g., number of loops, lines, pixel density in quadrants) after feature extraction.
The chart visually demonstrates how feature extraction significantly reduces the number of data points (from 784 to 15), making the data more manageable for a machine learning model while retaining essential information.
Significance of Feature Extraction
Feature extraction techniques are fundamental in machine learning and data science because they transform raw, complex data into a simplified, meaningful representation that enhances model performance and efficiency. These techniques are significant for several reasons:
- Dimensionality Reduction: Feature extraction reduces the number of input variables by selecting or creating a smaller set of informative features. For instance, in the handwritten digit example from the MNIST dataset, reducing 784 pixel values to 10-20 key features (e.g., loops, lines) lowers computational complexity, making models faster and less resource-intensive.
- Improved Model Performance: By focusing on relevant patterns and eliminating noise or redundant data (e.g., background pixels in images), feature extraction enhances a model’s ability to generalize, reducing overfitting and improving accuracy in tasks like classification or regression.
- Enhanced Interpretability: Extracted features, such as word embeddings in text analysis or edge detections in images, are often more interpretable than raw data, allowing domain experts to better understand and validate model behavior.
- Handling High-Dimensional Data: In domains like image processing, natural language processing, or genomics, raw data can have thousands or millions of dimensions. Feature extraction techniques, such as principal component analysis (PCA) or convolutional neural networks (CNNs), make it feasible to process such data efficiently.
- Noise Reduction: Feature extraction filters out irrelevant or noisy data, such as irrelevant pixels in an image or stop words in text, ensuring models focus on discriminative information, which leads to more robust predictions.
- Versatility Across Domains: These techniques are adaptable to various data types—images (e.g., extracting edges via CNNs), text (e.g., TF-IDF or word embeddings), audio (e.g., Mel-frequency cepstral coefficients), or time-series data—making them essential across diverse applications.
- Facilitating Transfer Learning: In deep learning, feature extraction enables the use of pre-trained models (e.g., BERT for text or ResNet for images) to extract high-level features, which can be fine-tuned for specific tasks, saving time and resources.
Techniques for Feature Extraction
Feature extraction techniques are methods used to transform raw data into a reduced set of meaningful features that capture essential patterns for machine learning tasks. Below is a concise overview of key techniques, categorized by their approach and application:
- Feature Extraction Techniques for Image Data
In image processing, feature extraction is crucial for recognizing patterns, objects, or textures in visual data. One popular technique is the Histogram of Oriented Gradients (HOG), which captures edge directions by computing gradient orientations in localized portions of an image—commonly used in human detection. Scale-Invariant Feature Transform (SIFT) and Speeded-Up Robust Features (SURF) are techniques that detect and describe local keypoints, remaining stable across changes in scale, rotation, and illumination.
They are widely used in object recognition and image stitching. Another effective method is Local Binary Patterns (LBP), which extracts texture features by comparing each pixel with its neighborhood and encoding it into binary codes. This method is particularly useful in facial recognition and texture classification. Additionally, color histograms are used to represent the distribution of colors in an image, capturing global color information irrespective of object shape or position. These techniques convert complex image data into numerical feature vectors that machine learning models can easily interpret.
2. Feature Extraction Techniques for Text Data
Text data is inherently unstructured and must be transformed into a numerical form before applying machine learning. The Bag of Words (BoW) model is a fundamental approach that represents text as a frequency distribution of words, ignoring grammar and word order. While simple, it provides a strong baseline for many text classification tasks.
To improve on BoW, TF-IDF (Term Frequency–Inverse Document Frequency) assigns weight to words based on their importance in a document relative to the entire corpus, helping to reduce the influence of common but less informative words. For deeper semantic understanding, word embeddings like Word2Vec, GloVe, and FastText map words into dense vector spaces where similar meanings are represented by closer vectors.
These embeddings preserve contextual and semantic relationships between words. Additionally, n-grams (combinations of consecutive n words) help capture local syntactic patterns and are useful in tasks like sentiment analysis or spam detection. These methods convert text into rich, high-dimensional vectors suitable for training advanced NLP models.
3. Feature Extraction Techniques for Time-Series and Signal Data
Time-series and signal data, such as audio, ECG, or sensor data, require specialized techniques to capture both temporal and frequency characteristics. The Fourier Transform is a classical method that converts signals from the time domain into the frequency domain, revealing underlying periodicities and dominant frequencies.
This is especially valuable in fields like speech recognition or vibration analysis. The Wavelet Transform provides a more detailed, time-localized analysis by breaking the signal into components at different frequency scales, making it useful for non-stationary data like EEG signals.
Besides transformations, statistical feature extraction involves computing time-domain characteristics like mean, variance, standard deviation, skewness, and kurtosis, which summarize the shape and variability of the signal. Auto-Regressive (AR) models estimate current signal values based on past values and are often used in financial forecasting and control systems. These techniques reduce raw signal complexity and highlight patterns essential for detection, classification, or prediction tasks.
4. Feature Extraction Techniques for Tabular (Numeric) Data
For structured numeric datasets typically found in spreadsheets or databases, feature extraction focuses on transforming and reducing features to enhance learning. Principal Component Analysis (PCA) is a powerful dimensionality reduction technique that identifies the directions (principal components) of maximum variance and projects the data onto them, retaining the most informative features while reducing dimensionality.
Linear Discriminant Analysis (LDA) is another technique that reduces dimensions but also maximizes the separability between classes, making it highly effective for classification problems. t-SNE and UMAP are non-linear dimensionality reduction techniques that visualize high-dimensional data in 2D or 3D while preserving local and global structure, although they are more often used for visualization than model training.
Additionally, feature construction involves creating new features from existing ones using domain knowledge—for instance, computing the ratio, difference, or product of numeric variables. This can reveal hidden relationships and improve model performance. Such feature engineering often plays a critical role in achieving state-of-the-art results in predictive modeling with tabular data.
The choice of feature extraction technique depends heavily on the data type and the specific task at hand. Each method serves to convert raw, often unstructured data into a structured, meaningful representation that enables machine learning algorithms to perform efficiently and accurately.