In some cases, while working a Pandas dataframe, you may get a kick out of the chance to subset the dataframe by keeping or hanging different segments. In this post, we will see instances of dropping different sections from a Pandas dataframe. We can drop segments in a couple of ways. We will utilize Pandas drop() capacity to figure out how to drop various segments and get a more modest Pandas dataframe.
I realize how to drop segments from an information outline utilizing Python. However, for my concern the informational index is huge, the segments I need to drop are assembled or are fundamentally uniquely fanned out across the section heading hub. Is there a more limited method for cutting or dropping every one of the segments with fewer lines of code as opposed to working it out like how I have done? The manner in which I have done it here works yet I might want a more summed up way.
We should examine how to drop one or different sections in Pandas Dataframe. Drop one or beyond what one segments from a DataFrame can be accomplished in more ways than one. Make a straightforward dataframe with word reference of records, say segment names are A, B, C, D, E.
Consideration! Reinforce your establishments with the Python Programming Foundation Course and gain proficiency with the essentials. In the first place, your meeting arrangements Enhance your Data Structures ideas with the Python DS Course. Also in the first place your Machine Learning Journey, join the Machine Learning – Basic Level Course
What are pandas in Python?
pandas is a python bundle for information control. It has a few capacities for the accompanying information assignments:
- Drop or Keep lines and sections
- Total information by at least one segments
- Sort or reorder information
- Blend or add different dataframes
- String Functions to deal with text information
- DateTime Functions to deal with date or time design segments
# Import pandas package import pandas as pd # create a dictionary with five fields eachdata = { 'A':['A1', 'A2', 'A3', 'A4', 'A5'], 'B':['B1', 'B2', 'B3', 'B4', 'B5'], 'C':['C1', 'C2', 'C3', 'C4', 'C5'], 'D':['D1', 'D2', 'D3', 'D4', 'D5'], 'E':['E1', 'E2', 'E3', 'E4', 'E5'] } # Convert the dictionary into DataFrame df = pd.DataFrame(data) df |
Output:

Method #1: Drop Columns from a Dataframe using drop() method.
Remove specific single column.
# Import pandas package import pandas as pd # create a dictionary with five fields each data = { 'A':['A1', 'A2', 'A3', 'A4', 'A5'], 'B':['B1', 'B2', 'B3', 'B4', 'B5'], 'C':['C1', 'C2', 'C3', 'C4', 'C5'], 'D':['D1', 'D2', 'D3', 'D4', 'D5'], 'E':['E1', 'E2', 'E3', 'E4', 'E5'] } # Convert the dictionary into DataFrame df = pd.DataFrame(data) # Remove column name 'A'df.drop(['A'], axis = 1) |
Output:

Remove specific multiple columns.
# Import pandas package import pandas as pd # create a dictionary with five fields eachdata = { 'A':['A1', 'A2', 'A3', 'A4', 'A5'], 'B':['B1', 'B2', 'B3', 'B4', 'B5'], 'C':['C1', 'C2', 'C3', 'C4', 'C5'], 'D':['D1', 'D2', 'D3', 'D4', 'D5'], 'E':['E1', 'E2', 'E3', 'E4', 'E5'] } # Convert the dictionary into DataFrame df = pd.DataFrame(data) # Remove two columns name is 'C' and 'D'df.drop(['C', 'D'], axis = 1) # df.drop(columns =['C', 'D']) |
Output:
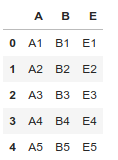
Remove columns as based on column index.
# Import pandas package import pandas as pd # create a dictionary with five fields eachdata = { 'A':['A1', 'A2', 'A3', 'A4', 'A5'], 'B':['B1', 'B2', 'B3', 'B4', 'B5'], 'C':['C1', 'C2', 'C3', 'C4', 'C5'], 'D':['D1', 'D2', 'D3', 'D4', 'D5'], 'E':['E1', 'E2', 'E3', 'E4', 'E5'] } # Convert the dictionary into DataFrame df = pd.DataFrame(data) # Remove three columns as index basedf.drop(df.columns[[0, 4, 2]], axis = 1, inplace = True) df |
Output:

Method #2: Drop Columns from a Dataframe using iloc[] and drop() method.
Remove all columns between a specific column to another columns.
# Import pandas package import pandas as pd# create a dictionary with five fields each data = { 'A':['A1', 'A2', 'A3', 'A4', 'A5'], 'B':['B1', 'B2', 'B3', 'B4', 'B5'], 'C':['C1', 'C2', 'C3', 'C4', 'C5'], 'D':['D1', 'D2', 'D3', 'D4', 'D5'], 'E':['E1', 'E2', 'E3', 'E4', 'E5'] } # Convert the dictionary into DataFrame df = pd.DataFrame(data) # Remove all columns between column index 1 to 3df.drop(df.iloc[:, 1:3], inplace = True, axis = 1) df |
Output:

Method #3: Drop Columns from a Dataframe using ix() and drop() method.
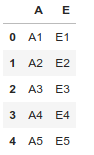
Remove all columns between a specific column name to another columns name.
# Import pandas package import pandas as pd # create a dictionary with five fields each data = { 'A':['A1', 'A2', 'A3', 'A4', 'A5'], 'B':['B1', 'B2', 'B3', 'B4', 'B5'], 'C':['C1', 'C2', 'C3', 'C4', 'C5'], 'D':['D1', 'D2', 'D3', 'D4', 'D5'], 'E':['E1', 'E2', 'E3', 'E4', 'E5'] } # Convert the dictionary into DataFrame df = pd.DataFrame(data) # Remove all columns between column name 'B' to 'D'df.drop(df.ix[:, 'B':'D'].columns, axis = 1) |
Output:
Method #4: Drop Columns from a Dataframe using loc[] and drop() method.
Remove all columns between a specific column name to another columns name.
# Import pandas package import pandas as pd # create a dictionary with five fields each data = { 'A':['A1', 'A2', 'A3', 'A4', 'A5'], 'B':['B1', 'B2', 'B3', 'B4', 'B5'], 'C':['C1', 'C2', 'C3', 'C4', 'C5'], 'D':['D1', 'D2', 'D3', 'D4', 'D5'], 'E':['E1', 'E2', 'E3', 'E4', 'E5'] } # Convert the dictionary into DataFrame df = pd.DataFrame(data) # Remove all columns between column name 'B' to 'D'df.drop(df.loc[:, 'B':'D'].columns, axis = 1) |
Output:

Note: Different loc() and iloc() is iloc() exclude last column range element.\
Method #5: Drop Columns from a Dataframe by iterative way.
Remove all columns between a specific column name to another columns name.
# Import pandas package import pandas as pd # create a dictionary with five fields each data = { 'A':['A1', 'A2', 'A3', 'A4', 'A5'], 'B':['B1', 'B2', 'B3', 'B4', 'B5'], 'C':['C1', 'C2', 'C3', 'C4', 'C5'], 'D':['D1', 'D2', 'D3', 'D4', 'D5'], 'E':['E1', 'E2', 'E3', 'E4', 'E5'] } # Convert the dictionary into DataFrame df = pd.DataFrame(data)for col in df.columns: if 'A' in col: del df[col] df |
Output:
