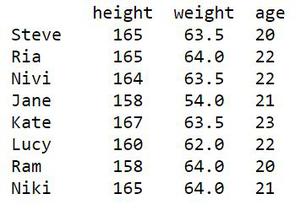
We should perceive How to Count Distinct Values of a Pandas Dataframe Column? Consider a plain construction as given beneath which must be made as Dataframe. The sections are stature, weight and age. The records of 8 understudies structure the lines. Consideration nerd! Reinforce your establishments with the Python Programming Foundation Course and become familiar with the essentials. In any case, your meeting arrangements Enhance your Data Structures ideas with the Python DS Course. Also in any case your Machine Learning Journey, join the Machine Learning – Basic Level Course.
By and large, the information in every section addresses an alternate element of the dataframe. It very well might be ceaseless, unmitigated, or something entirely unexpected like particular texts. Assuming that you don’t know about the idea of the qualities you’re managing, it very well may be a decent exploratory advance to be aware of the count of unmistakable qualities. In this instructional exercise, we’ll see how to get the include of one of a kind qualities in every section of a pandas dataframe.
How to Count Distinct Values of a Pandas
Utilizing the pandas dataframe nunique() work with default boundaries gives a count of the relative multitude of unmistakable qualities in every section. ,Pandas – Count of Unique Values in Each Column,In the above model, the nunique() work returns a pandas Series with includes of unmistakable qualities in every section. Note that, for section D we just have two unmistakable qualities as the nunique() work, as a matter of course, overlooks all NaN values.,To count the one of a kind upsides of every segment of a dataframe, you can utilize the pandas dataframe nunique() work. Coming up next is the grammar:
To count the extraordinary upsides of every section of a dataframe, you can utilize the pandas dataframe nunique() work. Coming up next is the language structure:
counts = df.nunique()
| height | weight | age | |
| Steve | 165 | 63.5 | 20 |
| Ria | 165 | 64 | 22 |
| Nivi | 164 | 63.5 | 22 |
| Jane | 158 | 54 | 21 |
| Kate | 167 | 63.5 | 23 |
| Lucy | 160 | 62 | 22 |
| Ram | 158 | 64 | 20 |
| Niki | 165 | 64 | 21 |
The first step is to create the Dataframe for the above tabulation. Look at the code snippet below.
- Python3
# import libraryimport pandas as pd # create a Dataframedf = pd.DataFrame({ 'height' : [165, 165, 164, 158, 167, 160, 158, 165], 'weight' : [63.5, 64, 63.5, 54, 63.5, 62, 64, 64], 'age' : [20, 22, 22, 21, 23, 22, 20, 21]}, index = ['Steve', 'Ria', 'Nivi', 'Jane', 'Kate', 'Lucy', 'Ram', 'Niki']) # show the Dataframedf |
Output:
Strategy 1: Using for circle.
The Dataframe has been made and one can hard coded utilizing for circle and count the quantity of interesting qualities in a particular segment. For instance In the above table, on the off chance that one wishes to count the quantity of extraordinary qualities in the section tallness. The thought is to utilize a variable cnt for putting away the count and a rundown visited that has the recently visited values. Then, at that point, for circle that emphasizes through the ‘tallness’ section and for each worth, it checks whether a similar worth has effectively been visited in the visited list. In case the worth was not visited beforehand, then, at that point, the count is increased by 1.
Below is the implementation:
- Python3
# import libraryimport pandas as pd # create a Dataframedf = pd.DataFrame({ 'height' : [165, 165, 164, 158, 167, 160, 158, 165], 'weight' : [63.5, 64, 63.5, 54, 63.5, 62, 64, 64], 'age' : [20, 22, 22, 21, 23, 22, 20, 21]}, index = ['Steve', 'Ria', 'Nivi', 'Jane', 'Kate', 'Lucy', 'Ram', 'Niki']) # variable to hold the countcnt = 0 # list to hold visited valuesvisited = [] # loop for counting the unique# values in heightfor i in range(0, len(df['height'])): if df['height'][i] not in visited: visited.append(df['height'][i]) cnt += 1 print("No.of.unique values :", cnt) print("unique values :", visited) |
Output :
No.of.unique values : 5 unique values : [165, 164, 158, 167, 160]
But this method is not so efficient when the Dataframe grows in size and contains thousands of rows and columns. To give an efficiency there are three methods available which are listed below:
- pandas.unique()
- Dataframe.nunique()
- Series.value_counts()
Method 2: Using unique().
The unique method takes a 1-D array or Series as an input and returns a list of unique items in it. The return value is a NumPy array and the contents in it are based on the input passed. If indices are supplied as input, then the return value will also be the indices of the unique value.
Syntax: pandas.unique(Series)
Example:
- Python3
# import libraryimport pandas as pd # create a Dataframedf = pd.DataFrame({ 'height' : [165, 165, 164, 158, 167, 160, 158, 165], 'weight' : [63.5, 64, 63.5, 54, 63.5, 62, 64, 64], 'age' : [20, 22, 22, 21, 23, 22, 20, 21]}, index = ['Steve', 'Ria', 'Nivi', 'Jane', 'Kate', 'Lucy', 'Ram', 'Niki']) # counting unique valuesn = len(pd.unique(df['height'])) print("No.of.unique values :", n) |
Output:
No.of.unique values : 5
Method 3: Using Dataframe.nunique().
This method returns the count of unique values in the specified axis. The syntax is :
Syntax: Dataframe.nunique (axis=0/1, dropna=True/False)
Example:
- Python3
# import libraryimport pandas as pd # create a Dataframedf = pd.DataFrame({ 'height' : [165, 165, 164, 158, 167, 160, 158, 165], 'weight' : [63.5, 64, 63.5, 54, 63.5, 62, 64, 64], 'age' : [20, 22, 22, 21, 23, 22, 20, 21]}, index = ['Steve', 'Ria', 'Nivi', 'Jane', 'Kate', 'Lucy', 'Ram', 'Niki']) # check the values of # each row for each columnn = df.nunique(axis=0) print("No.of.unique values in each column :\n", n) |
Output:
No.of.unique values in each column : height 5 weight 4 age 4 dtype: int64
To get the number of unique values in a specified column:
Syntax: Dataframe.col_name.nunique()
Example:
- Python3
# import libraryimport pandas as pd # create a Dataframedf = pd.DataFrame({ 'height' : [165, 165, 164, 158, 167, 160, 158, 165], 'weight' : [63.5, 64, 63.5, 54, 63.5, 62, 64, 64], 'age' : [20, 22, 22, 21, 23, 22, 20, 21]}, index = ['Steve', 'Ria', 'Nivi', 'Jane', 'Kate', 'Lucy', 'Ram', 'Niki']) # count no. of unique # values in height columnn = df.height.nunique() print("No.of.unique values in height column :", n) |
Output:
No.of.unique values in height column : 5
Method 3: Using Series.value_counts().
This method returns the count of all unique values in the specified column.
Syntax: Series.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
Example:
- Python3
# import libraryimport pandas as pd # create a Dataframedf = pd.DataFrame({ 'height' : [165, 165, 164, 158, 167, 160, 158, 165], 'weight' : [63.5, 64, 63.5, 54, 63.5, 62, 64, 64], 'age' : [20, 22, 22, 21, 23, 22, 20, 21]}, index = ['Steve', 'Ria', 'Nivi', 'Jane', 'Kate', 'Lucy', 'Ram', 'Niki']) # getting the list of unique valuesli = list(df.height.value_counts()) # print the unique value countsprint("No.of.unique values :", len(li)) |
Output:
No.of.unique values : 5 Also Read: How to split a string in C/C++, Python and Java?