Table of Contents
Reducing Noise Effects with Hysteresis
How to reduce noise effects in comparator circuits? Reducing noise with hysteresis in a voltage comparator circuit is important otherwise it will cause unwanted triggering. A whimsical yield voltage brought about by clamor on the info happens on the grounds that the operation amp comparator changes from its negative yield state to its positive yield state at a similar info voltage level that makes it switch in the inverse course, from positive to negative. This precarious condition happens when the information voltage drifts around the reference voltage, and any little clamor changes cause the comparator to switch initial one way and afterward the other.
To make the comparator less delicate to clamor, a strategy fusing positive input, called hysteresis, can be utilized. Fundamentally, hysteresis implies that there is a higher reference level when the information voltage goes from a lower to higher incentive than when it goes from a higher to a lower esteem. A genuine illustration of hysteresis is a typical family unit indoor regulator that turns the heater on at one temperature and off at another.
How to reduce noise with hysteresis in voltage comparator?
In order to reduce noise with hysteresis in comparator circuit the following procedure is followed. The two reference levels are alluded to as the upper trigger point (UTP) and the lower trigger point (LTP). This two-level hysteresis is set up with a positive criticism game plan, as appeared in Figure below. Notice that the noninverting input is associated to a resistive voltage divider with the end goal that a bit of the yield voltage is taken care of back to the input. The information signal is applied to the altering (- ) contribution to this case.
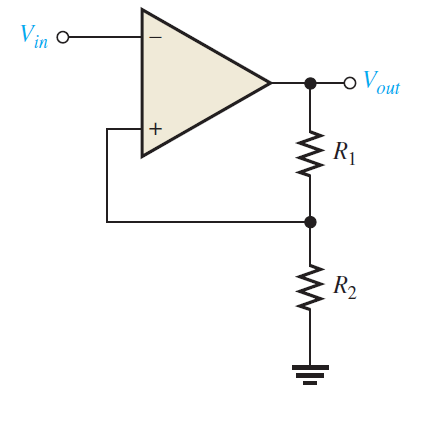
The essential activity of the comparator with hysteresis is outlined in Figure below. Expect that the yield voltage is at its positive greatest, Vout(max). The voltage took care of back to the noninverting input is VUTP and is communicated as
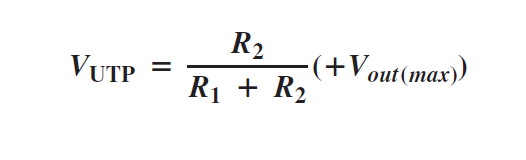
A comparator with hysteresis
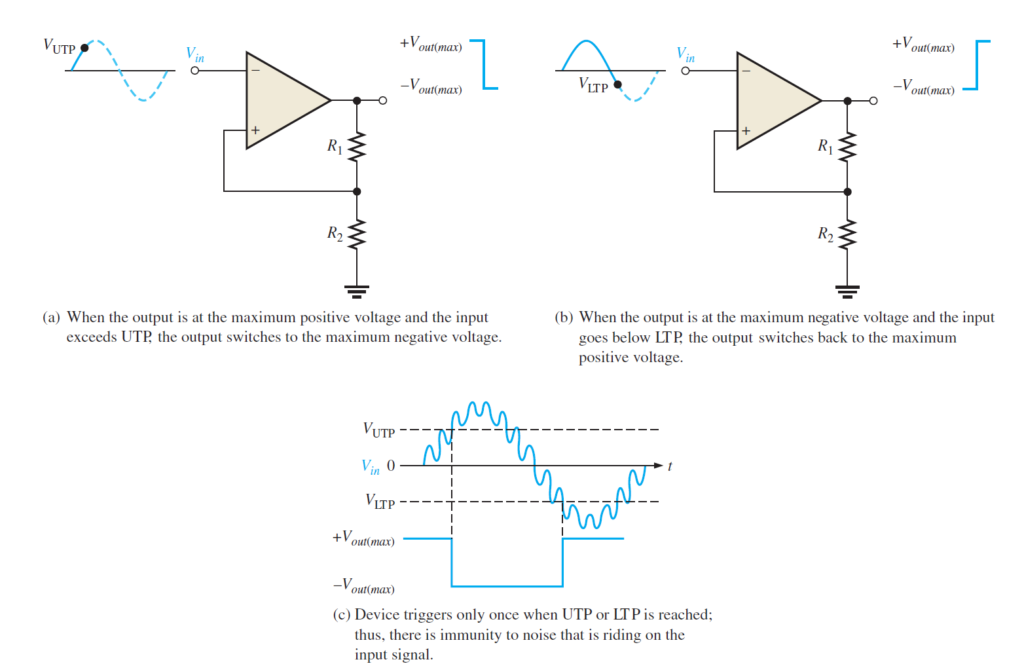
At the point when Vin surpasses VUTP, the yield voltage drops to its negative most extreme, as appeared to some degree in below figure(a). Presently the voltage took care of back to the noninverting input is VLTP and is communicated as
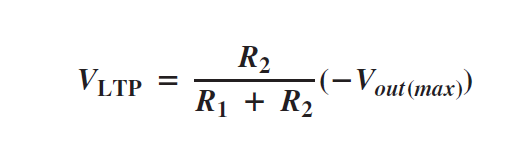
The information voltage should now fall beneath VLTP, as appeared to some extent (b), before the gadget will change from the greatest negative voltage back to the most extreme positive voltage. This implies that a modest quantity of clamor voltage has no impact on the yield, as delineated by Figure (c) above. A comparator with worked in hysteresis is at times known as a Schmitt trigger. The measure of hysteresis is characterized by the distinction of the two trigger levels.
![]()
Output Bounding
In certain applications, it is important to restrict the yield voltage levels of a comparator to a esteem not as much as that gave by the soaked operation amp. A solitary zener diode can be utilized, as appeared in below Figure , to restrict the yield voltage to the zener voltage one way and to the forward diode voltage drop in the other. This cycle of restricting the yield range is called bounding.
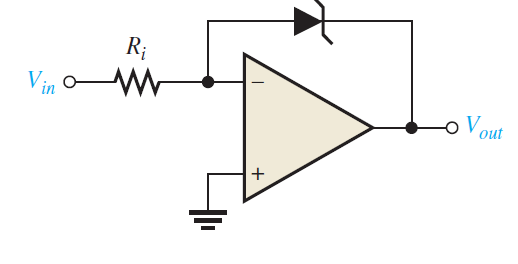
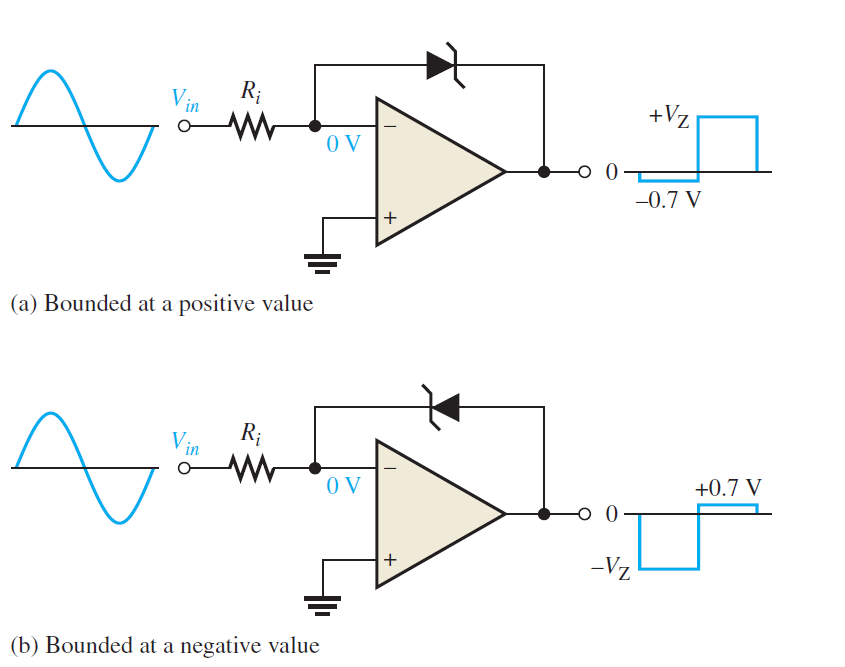
The activity is as per the following. Since the anode of the zener is associated with the modifying input, it is at virtual ground Therefore, when the yield voltage comes to a positive worth equivalent to the zener voltage, it limits at that esteem, as shown in Figure (a) below. At the point when the yield switches negative, the zener goes about as a normal diode and becomes forward-one-sided at 0.7 V, restricting the negative yield voltage to this worth, as appeared to a limited extent (b). Turning the zener around limits the yield voltage the other way.
Also read here
https://eevibes.com/design-of-voltage-comparator-with-op-amp/